上次实现的是Per-pixel Linked Lists方法,能做到高效地在单pass内剥离多层物体,但内存消耗不可控,而且性能和每个pixel的fragment list长度很有关系。HPG 2011上intel有个改进的方法,称为Adaptive Transparency(AT),号称能在可控的内存内做到稳定的性能和高质量的OIT。于是我打算实现一下这个方法。
方法描述
AT首先从alpha blending的方程本身下手。Alpha blending需要一个迭代的过程:
[latex]C_{n} = \alpha_{n} C_{n}+(1-\alpha_{n}) C_{n-1}[/latex]
透明渲染需要按照顺序,也就是因为这个迭代所致。AT引入了一个可见性函数
[latex]vis(z) = \prod_{0<z_{i}<z}(1-\alpha_{i})[/latex]
于是alpha blending方程就能重构成一个简单的累加
[latex]\sum_{i=0}^n c_{i} \alpha_{i} vis(z_{i})[/latex]
那么就可以不考虑顺序了。
接着,AT又采用了近似的方法,不必求出精确的vis(z),而是用几个阶跃函数来模拟。这样一来,每个pixel的近似vis(z)可以存入一个固定大小的数组中,内存消耗也控制住了,同时能很好地逼近Per-pixel Linked List的结果。具体方法可以参考intel的paper和ppt。
理想状况
在理想状况中,AT算法可以表示成:
- 渲染物体,把pixel的vis(z)存入frame buffer中;
- 累加c*a*vis(z),求出最终结果。
很遗憾的是,frame buffer对于一个pixel的存储空间很有限,无法负担存储足够的vis(z),于是轮到了UAV。遗憾的是,vis(z)本身的存储是要求对一个有序链表进行插入操作,所以需要有原子地访问到整条链表的能力。而目前的硬件和API不能支持这样的操作。
现实状况
现在回到现实,在DX11级别的硬件和API上,要实现AT,就需要把算法调整成三步:
- 渲染物体,PS计算出shading后的颜色,让fragments buffer自带的计数器加一,得到一个空间后把颜色和深度存进去,同时更新该像素位置对应的start offset buffer;
- 读取pixel的整条fragment链表,计算vis(z),存入临时数组;
- 从临时数组读取vis(z),累加c*a*vis(z),求出最终结果。
其中,第一步和Per-pixel Linked Lists完全相同,第二步和第三步在一个post process里完成。所以总的来看,AT只要在Per-pixel Linked Lists的基础上略加修改即可,很容易实现。在简单场景上性能达到65.84FPS,略高于Per-pixel Linked Lists的62.47FPS。随着复杂度的提高,性能提升会越来越明显。
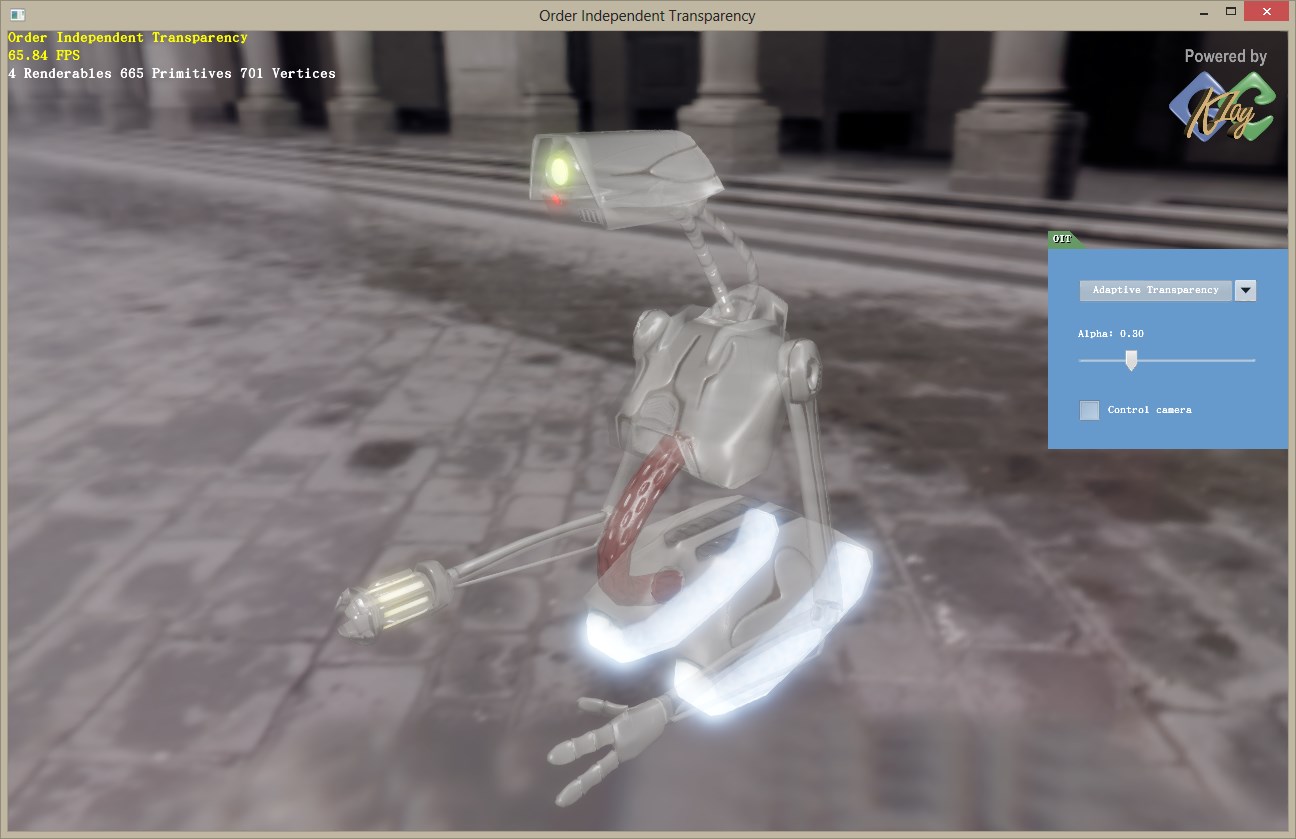
总结和未来
AT的计算复杂度和带宽要求都好于Per-pixel Linked Lists,是一个很不错的OIT方法。缺点是它是一种近似,在一些时候会出现一定的误差。I3D2013上将会出现一篇叫做Hybrid Transparency的论文,等放出来以后才能知道结果如何。



Comments