KlayGE从4.0开始引入deferred rendering层(DR),并且这几个版本都在持续地改进,以提高性能和降低使用难度。在即将发布的4.4里,deferred rendering更是往前跨了一大步,实现了一个初步的Tile-based Deferred Rendering(TBDR)。和常见的TBDR不同之处在于,这里的方法只需要SM3。(其实SM2也没问题,只是如果光源较多,会遇到指令长度限制)
Tile-based
在传统的deferred rendering中,每个光源需要和每个像素做一次相交测试,测试通过的才计算光照。这个相交测试一般通过light volume的方式进行优化。但最终仍然需要对每个light画1次。也就是说,每个像素需要对每个光源读取一次G-Buffer,计算一个光照,并做一次blend写入。这个带来的带宽开销远大于forward rendering,使得在低带宽的设备,尤其是手机平板平台上,几乎没有办法使用deferred rendering。
Tile-based的核心思想是,把G-Buffer划分成等大小的tile(一般会用32×32),每个tile会维护一个列表。对于每个tile,从depth buffer可以算出它的bounding box。把光源分成N个一组,每个光源和每个tile的bounding box做一次相交测试,并把光源id放入tile的列表中。在lighting的时候,一个pass只需要读取一次G-Buffer,就能计算列表中所有光源的光照。而输出的时候只做一次blend写入。因为在GPU寄存器上读写的速度远高于读写显存,这么做直接能把带宽减少N倍。用流程图来表示,就是:
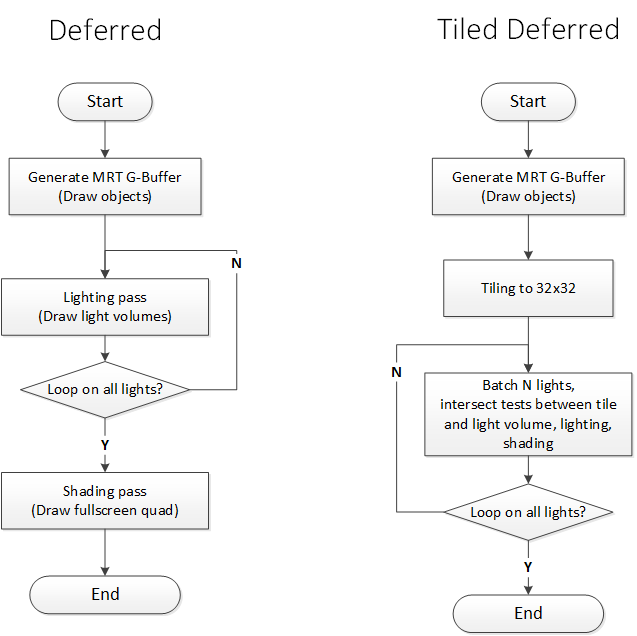
从这个流程图可以很明显看出两者的大体框架相同,但Tile-based能把N个pass变成shader里的N次循环,所以就有机会提高效率。
带宽比较
这里来一个带宽的定量比较。假设G-Buffer由2个ABGR8组成,depth buffer的格式是float,光源数量是L、分为N个一组。Lighting buffer的格式是ABGR16F,shading buffer的格式是B10G11R11F。那么可以比较一下平均一个pixel的带宽。
| Deferred | Tile-based Deferred | |
|---|---|---|
| Tiling读取带宽 | 0 | (32*32 + 2*(16*16 + 8*8 + 4*4 + 2*2)) / (32*32) * 4 = 6.66 |
| Tiling写入带宽 | 0 | 2*(16*16 + 8*8 + 4*4 + 2*2 + 1*1) / (32*32) * 4 = 2.66 |
| Lighting读取带宽 | L * (4 + 4) + L * 8 = L * 16 | L/N * (4 + 4) + L/N * 4 = L/N * 12 |
| Lighting写入带宽 | L * 8 | L/N * 4 |
| Shading读取带宽 | 8 | 0 |
| Shading写入带宽 | 4 | 0 |
| 总和 | L*24+12 | L/N*16+9.32 |
DR不需要tiling,所以tiling部分的带宽都是0。TBDR的shading已经合并到lighting pass了,不需要独立的shading pass。同时也是因为已经是shading了,不需要把diffuse和spacular分开,也不需要输出到ABGR16F四个通道(三个diffuse,一个specular的亮度),只要RGB三个通道足矣。
由于tiling和shading的带宽相比之下已经微不足道了,所以这里主要就看lighting部分。如果N比较大,可以很明显看出lighting的带宽占用会明显减少。在KlayGE 4.4的实现里,N=32,已经能把带宽消耗减少到类似forward的水平了。
一些实现细节
TBDR的实现在网上已经有很多文章和代码,这里就只讨论一些细节。
Tiling的方法很简单,类似于mipmap那样,把depth buffer每次减少1/2。但需要保存的是min和max两个depth值,这样才能构成bounding box。这个bounding box实际上是一个斜的视锥。可以用个off center的frustum构造方法求出来。详见Intel的例子。
在求交计算的时候,point light可以用球,spot light暂时用的是AABB。(其实spot最好使用cone和frustum求交,但我没找到相关算法)。在shader里把它们和tile的frustum做求交测试,也就是把原先CPU上的view frustum culling搬到shader里,per-tile执行。
重点在于,一般提到TBDR的地方说的都是用compute shader,至少也是具有任意写入能力的pixel shader 5,才能把这个列表保存到类似OIT的per-pixel linked lists里。但这样的话就失去了对老硬件和移动平台的支持(虽然下一代移动GPU就能支持完整的D3D11,但普及尚需时日)。KlayGE 4.4的方法是类似于light indexed rendering的做法,用个常见的ABGR8格式,每个light占用一个独立的bit组成32位的mask来保存这个列表。这么一来,就可以把32个光打包成一组,用这个固定长度的bit“列表”保存哪些光源对这个tile有影响。在不支持位运算的硬件上,可以用除法和求余来模拟出bit and操作,所以也能得到某个bit是否是1。
结果
最终实现的TBDR只需要用到SM3甚至SM2的shader,带宽减少32-64倍,瓶颈移到了计算上。而且,和原先的deferred rendering相比,只改了不到100行C++代码和100多行shader代码。任何一个deferred框架都可以轻松迁移到这个方法上。同时性能提升也是很明显的,目前可以轻松在低端硬件上实时渲染大量光源。
这里测试了720p的分辨率上,sponza场景在高端的GTX680分别使用DR和TBDR,每一帧所花费的毫秒数,横轴表示光源数。
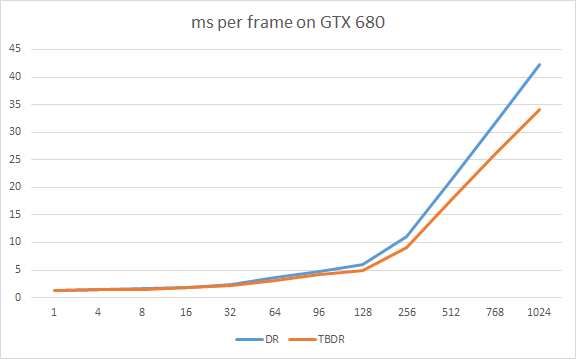
和理论分析一样,随着光源的增多,TBDR花费的时间也逐渐减少,到1024个光的时候已经能少20%了。注意这里的TBDR只是个算法验证,还没到优化的阶段。而DR已经经过多轮优化了。
在低端的NVS4200M上,这个差距就更明显了,差距可以超过50%:
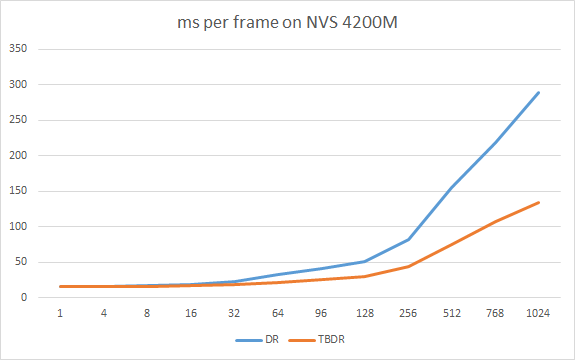
在KlayGE 4.4发布前,我会进一步优化TBDR,希望能有更好的表现。KlayGE 4.5中打算实现个compute shader的版本,把1024个light分成一组,基本上可以在一个pass算完所有的光照和着色。以后也会考虑更新的clusted deferred。
本篇讲了一个只需要SM3的TBDR,下一篇会将一些Deferred框架的其他改进。



Comments