上一篇讲了基于CS的TBDR,目前KlayGE中一共有三条deferred的code path,传统的DR,基于PS的TBDR和基于CS的TBDR。但不论是什么样的deferred,都不可避免需要在G-Buffer上存normal。对G-Buffer优化的重要议题之一也是如何尽量紧凑地存储normal。
原先的做法
在KlayGE 4.0之前,G-Buffer是2张64bpp的纹理,normal用spheremap transform的方式存在2个fp16的通道里,共32bit。这样的G-Buffer占用空间相当大。在4.0的时候,G-Buffer改成了2张32bpp的纹理,normal用best fit的方法存在3个8bit通道里,共24bit。Best fit的有效位数是23bit,两个fp16的总有效位数是22bit,所以这么做反而有助于质量提升。
Normal压缩
Normal的压缩其实应该分为两类。第一类是针对normal map的normal压缩,第二类是针对G-Buffer的normal压缩。两者看起来很相似,但其实有一些要求上的巨大区别。有些论文,比如Encoding Normal Vectors using Optimized Spherical Coordinates[1],并没有搞清楚这个区别,就直接把best fit normal和他们的normal map压缩作比较。结果必然是非常不公平的。
两种方法的侧重点可以这么来比较。
| 针对normal map | 针对G-Buffer | |
|---|---|---|
| 压缩位数 | 4bpp(BC1)或8bpp(BC3/BC5/BC7) | 16bpp或24bpp |
| normal空间 | 局部tangent space | 全局view space |
| 压缩格式 | 硬件支持的压缩格式 | 硬件支持的非压缩格式 |
| 执行位置 | CPU | GPU |
| 压缩速度 | 无所谓 | 较高 |
| 解压速度 | 较高 | 很高 |
针对normal map的压缩,normal是存在tangent space的。而从tangent space到model space还有一个TBN,实际位数是两者之和。所以即便压缩到非常少的位数,质量也不错。从这里可以看出,必须首先根据针对的目标选择压缩方法,两者不该互换或比较。
以下文章只讨论针对G-Buffer的方法。
Sphere map的回归
Best fit normal的主要缺点是,平均误差虽然很小,但最大误差达到了4度。而且需要额外读一次纹理,对带宽是个压力。最近的一篇论文A Survey of Efficient Representations
for Independent Unit Vectors[2]分析了几十种normal压缩方法,并且有详细的速度和质量的对比。有兴趣的朋友可以参考那篇论文。为了消除那些缺点,回归到spheremap transform似乎成了唯一的做法。如果能仍旧在24bit内,存储spheremap的2个通道,问题就解决了。
如果是个CPU程序,给你2个12bit的数,让你拼成3个8bit的数,是轻而易举的。只要把两者的高8位放到xy通道,两者的低4位拼成一个8位放到z通道,就完事了。对于GPU来说,需要考虑不支持位运算的DX9级别硬件,就得用浮点运算来模拟这件事情。代码如下所示.
| 编码 | 解码 |
|---|---|
| float2 enc255 = enc_spheremap * 255; float2 residual = floor(frac(enc255) * 16); float3 enc = float3(floor(enc255), residual.x * 16 + residual.y) / 255; |
float nz = floor(enc.z * 255) / 16; float2 dec = enc.xy + float2(floor(nz) / 16, frac(nz)) / 255; |
这样的另一个好处是,可以通过控制z通道的有效位数来测试不同位数对压缩质量的影响。根据[2]的表1,位数对误差的影响是决定性的。几种方法在位数相同时误差差别不大,而位数多2位基本能把误差降低一半。比如,最好的16bit方法,也比不上最差的20bit方法,更不用说24bit的了。我在实验中也发现了类似的现象。同样的位数,不同方法质量接近,不同位数的质量差别肉眼可见。这里比较模型是一个微凸的曲面,加上高光。这样能很明显看出normal质量的差别。
16bit
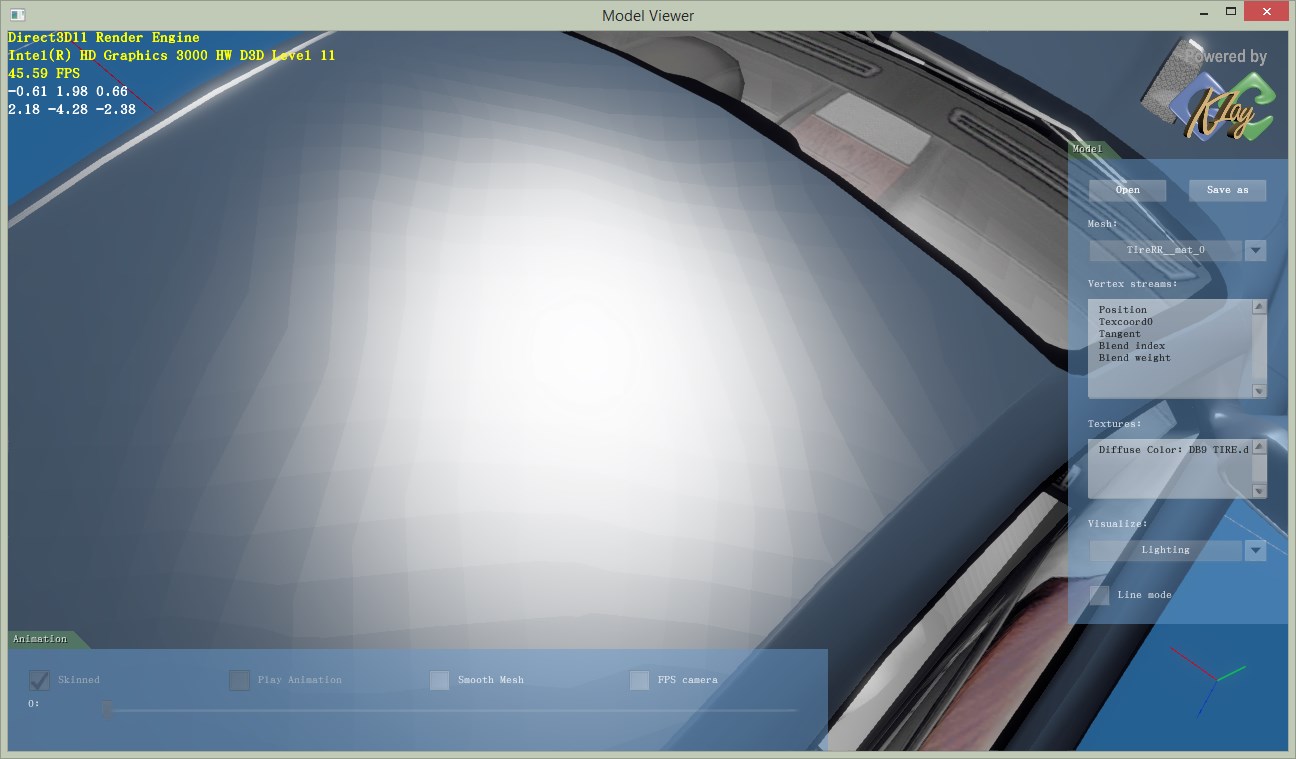 18bit
18bit
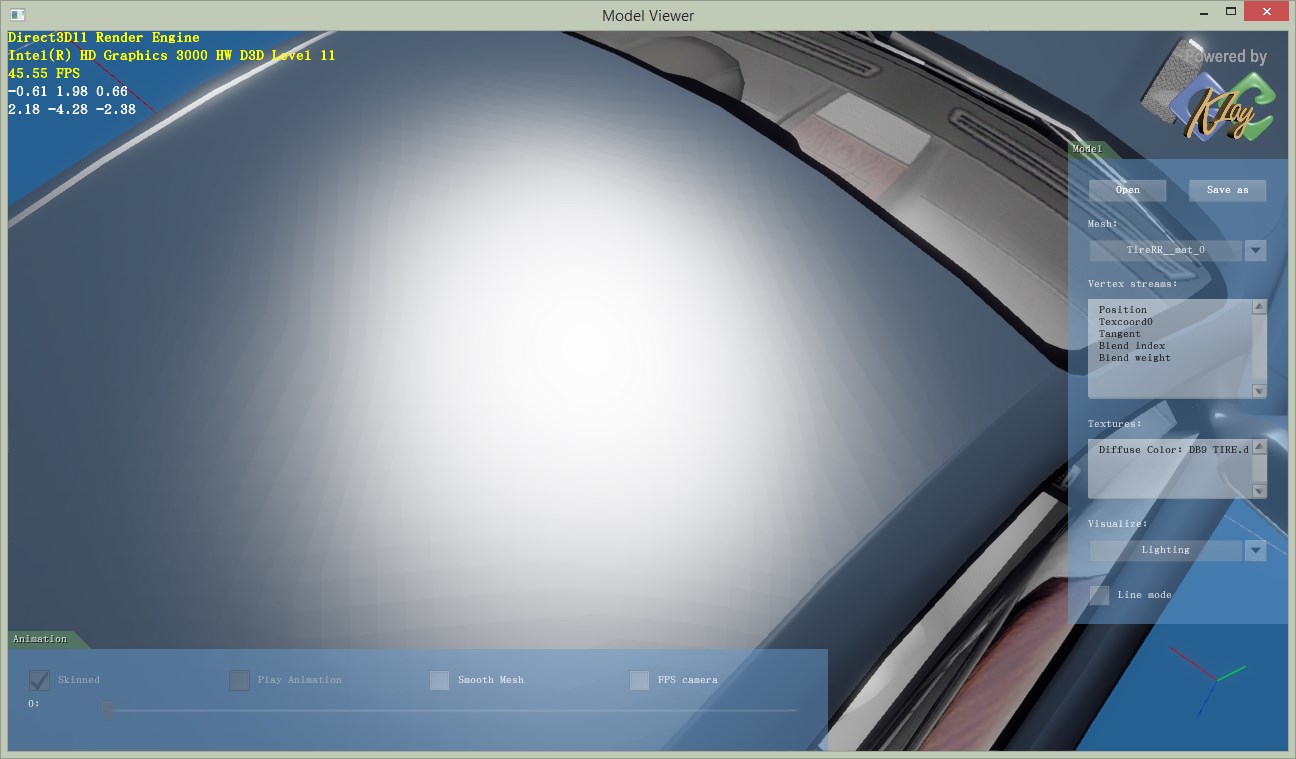 20bit
20bit
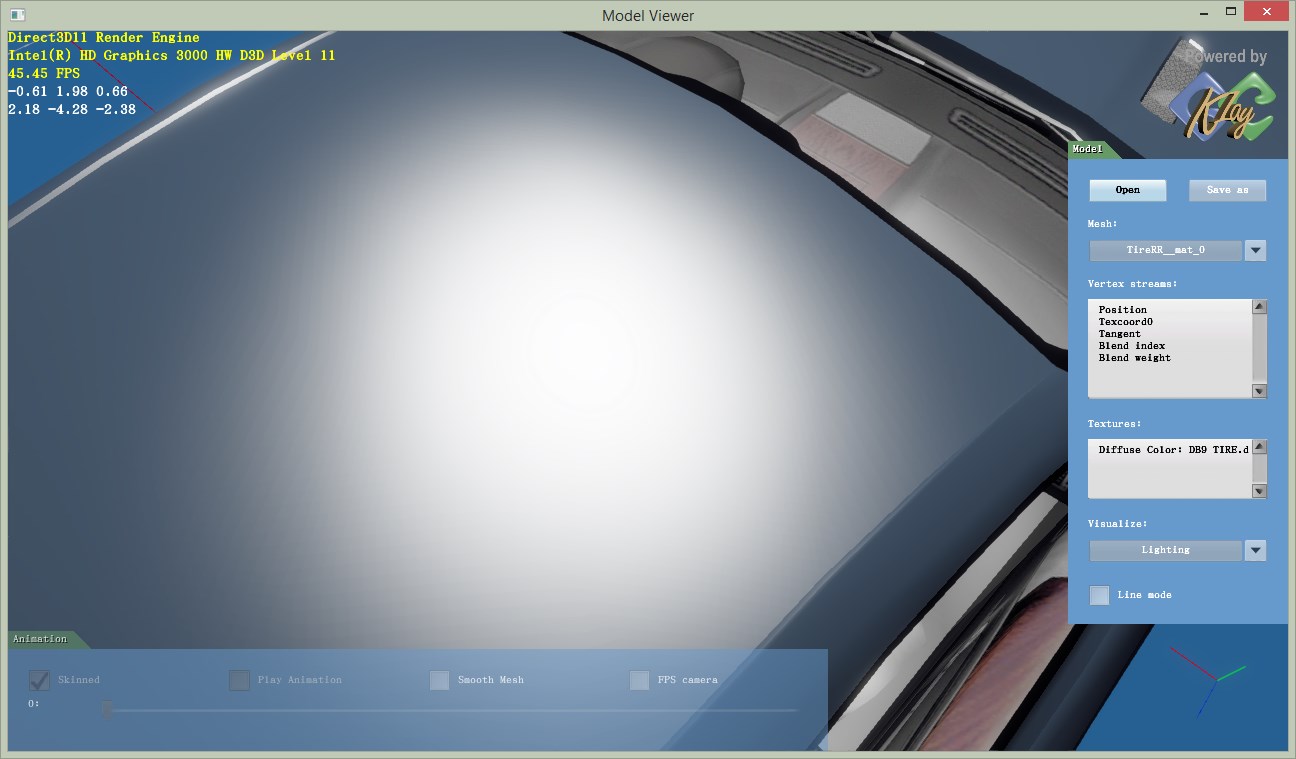 22bit
22bit
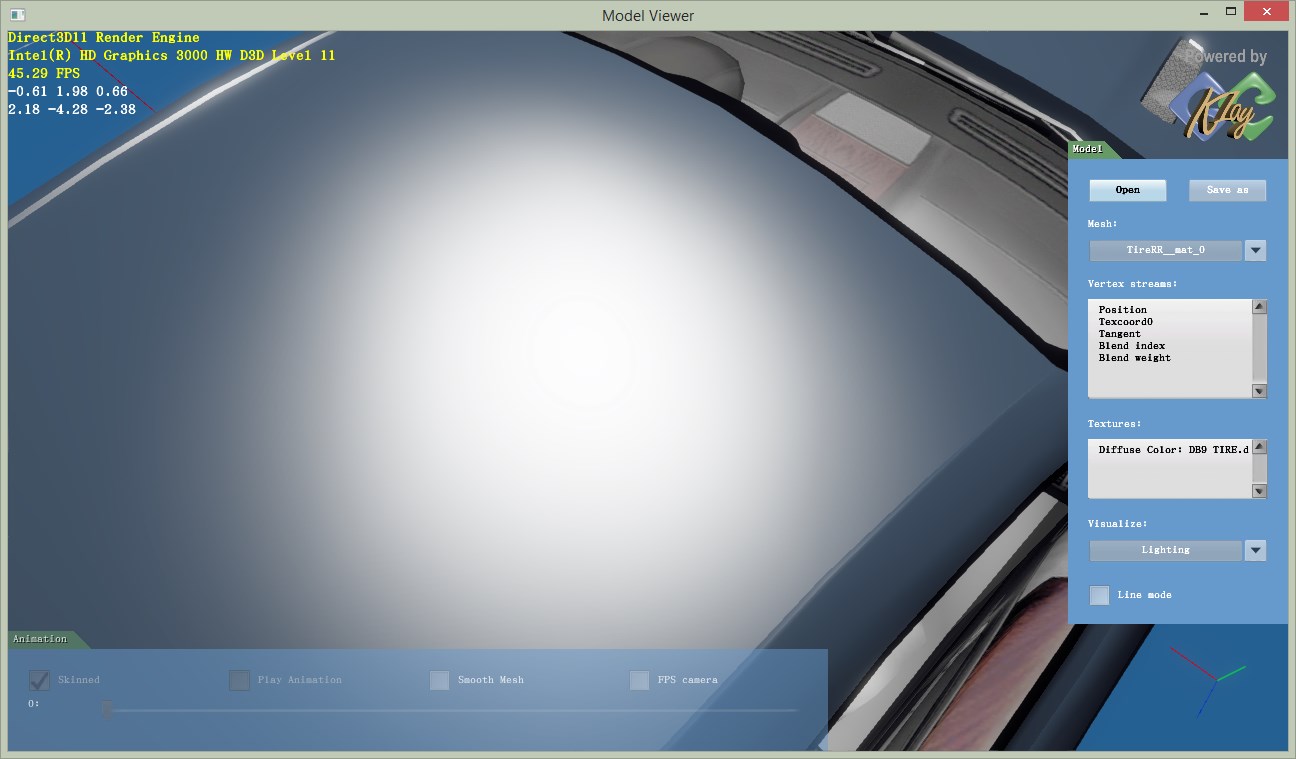 24bit
24bit
 结论是,要保证平滑,就得24bit,不用再奢望16bit了。
结论是,要保证平滑,就得24bit,不用再奢望16bit了。
总结
新的normal存储不需要读取纹理,同时计算量也很小。足以取代best fit。下一篇会继续讲渲染方面的改进,探讨一下如何在很低的配置上执行deferred rendering。



Comments