在游戏引擎里,每一帧都可能有UI和文字的渲染。这些东西的特点是,琐碎,随机,但每一部分的数据量很小。比如UI由很多矩形块组成,每个只有4个顶点。这样的数据对GPU来说是很头疼的。所以引擎往往需要在Buffer上做一些工作来改善渲染的性能。
由于在目前常见的架构上,CPU和GPU不能同时读写一块内存,CPU在写入数据的时候GPU只能读取另一个地方来渲染。所以一定需要某个机制,来避免这样的冲突。
常见方法1:Discard
最古老的一个做法就是,自己维护一块内存,每一次需要画东西的时候先放在那块内存中。每一帧用一次discard的方式对GPU buffer做一次map,把数据拷贝进去。这么做很简单,所有复杂的同步都交给驱动去完成。
在内部,discard避免CPU/GPU冲突的方式是申请一块新空间让CPU填充,而GPU同时渲染的是旧空间,用完之后抛弃。也就是常说的N buffering。这么做在驱动层面至少需要2倍的内存空间,加上自己维护的那块内存,就需要3倍空间。同时,由于空间的申请和释放并不快,每一帧都这么做对性能来说有一定影响。
常见方法2:No overwrite + Discard
自从图形API支持no overwrite了之后,就出现了一个新方法。不需要自己维护一块内存,而是在每次画东西的时候直接用no overwrite的方式map GPU buffer,把数据放进去。同时,记录下buffer是用了多少。如果已经满了,就用discard来map,抛弃旧有空间。
No overwrite避免CPU/GPU冲突的方式是由程序自己保证,CPU新的填充数据不覆盖到GPU需要用的数据,所以CPU和GPU总是在读写同一块内存的不同区域。这么做并不需要申请新空间,map的性能远高于discard。但是这么做仍会有不少时候会遇到空间满了需要discard。其实很多数据已经被GPU用完,完全可以复用而不必总discard。
更高效的方法:transient
重新考虑一下这个情景,可以发现如果是个CPU程序,需要反复申请和释放很多小块的内存,那么大家都会想到用memory pool。那么为何不把memory pool的思路用到这里来呢?GDC 2012上Don’t Throw it all Away: Efficient Buffer Management中的Transient buffer正是如此。不久以前KlayGE的团队成员林胜华实现了ppt中所说的transient buffer,目前UI和文字都已经转成了用这种buffer管理方式。
Transient和思路和memory pool一样,都是基于free list管理一块空间。区别在于,CPU的memory pool,free list就保存在那块空间里,每个item包含了下一个未分配区域的指针。对于GPU buffer来说,平常需要让GPU用来渲染,所以不能处于map状态。所以free list是在CPU端单独维护,而每个item包含的是未分配区域在GPU buffer中的偏移量。通过这样的间接转换,就能在CPU端管理GPU buffer中的空闲非空闲区域了。接口方面,transient buffer和memory pool也非常相似,主要都是Alloc和Dealloc。在Alloc的时候,需要通过no overwrite来map内部的GPU buffer,把数据拷贝进去。因为有free list标记所有空闲区域,所以这时候是可以非常安全地使用no overwrite,而不用担心数据覆盖问题。
使用transient buffer的时候,需要保存保存当前帧由Alloc返回的数据列表,渲染的时候需要一次遍历,逐个render。每一帧结束的时候,就可以调用Dealloc把已经渲染过的块释放掉。但因为GPU异步的特殊性,在释放数据上需要特别小心。每一帧CPU提交的draw,最多可能在3帧之后才真正被GPU使用。所以在transient buffer内部还需要维护一个列表,保存每一帧被Dealloc的数据,在3帧之后才真正把它标记成空闲区域。
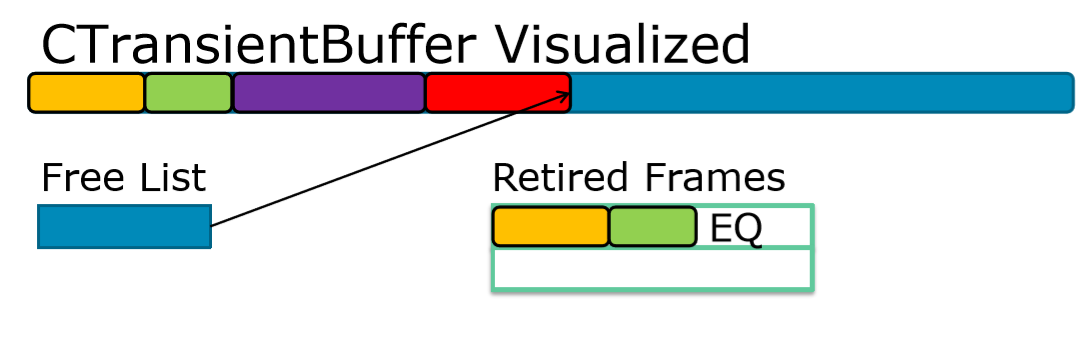
那么,还剩一个问题是,满了怎么办。一个做法是discard,再把整个区域当作空闲区域。另一个做法是申请一个更大的GPU buffer,把旧的数据拷贝过去,并加长free list。第一种做法如果遇到一次Alloc就需要大于整个buffer空间的情况,还是需要退化到第二种做法。所以目前KlayGE里只实现了第二种。
不支持no overwrite的平台
对于OpenGL 3.0之前而且不支持GL_ARB_map_buffer_range,或者OpenGL ES 3.0之前而且不支持GL_EXT_map_buffer_range的平台,是没有no overwrite的能力的。对于这样的平台,原文没涉及。在KlayGE中,遇到这种情况会在CPU端维护一个和GPU buffer一样大的vector,并在渲染之前通过discard的方式拷贝给真正的GPU buffer。这保证了对上层程序来说,不必考虑no overwrite的支持度。这也是KlayGE的实现对原文的一个扩展。
未来
在目前的D3D11上,也就只能做到这个程度了。如果未来需要进一步加速,在OpenGL上可以考虑用GL_ARB_buffer_storage提供的GL_MAP_PERSISTENT_BIT,做到CPU和GPU同时使用一块Buffer的目的。D3D12改善了这点,也能同时使用,解除了目前的读写冲突。
另一方面,对于particle system那样非常规则地申请和释放内存的情况,原文中还提供了一个叫做Discard-Free Temporary Buffers的方法,来自于StarCraft 2。比transient buffer更适合这种使用模式。在以后我们也会做一些尝试。



Comments